Getting Started with Ollama
AI has revolutionized how we work, helping with everything from coding to creative writing. However, many of these tools rely on internet access and third-party services, raising concerns about privacy and reliability when offline.
That’s where a local-first approach comes in, such as Ollama. It allows you to run AI using various LLMs directly on your computer without needing an internet connection.
Whether you’re a developer looking for assistance with code or someone exploring what AI can do, Ollama is a great tool to have in your toolkit. It supports a wide range of models and provides an API that you can use to interact with the models programmatically.
Installation
To get started with Ollama, you’ll need to install it on your computer.
Head over to the Download page and select the appropriate installer for your machine. It supports macOS, Windows, and Linux, and also comes with an official Docker image.
If you’re using macOS, you could also install it with Homebrew by running the command below:
brew install ollama
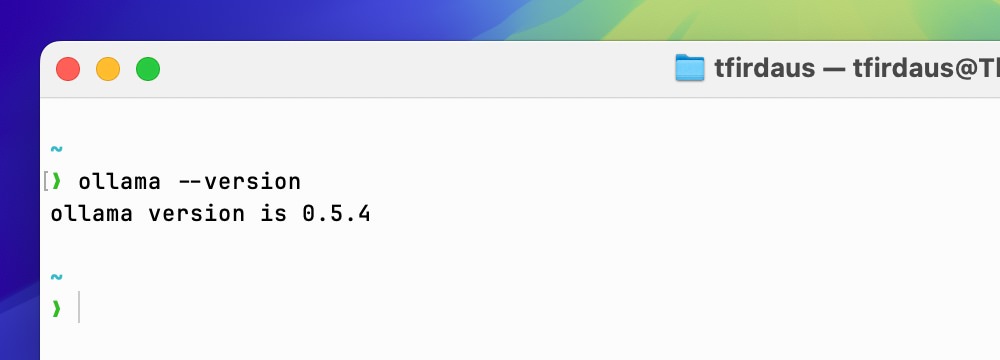
Once the installation is complete, you can verify it by running ollama --version in your terminal to see the current version installed.
Running Ollama
Now that we have Ollama installed, we can start running an LLM with it. We can pick an LLM from their Models library.
In this example, we’ll run the llama3.2 model.
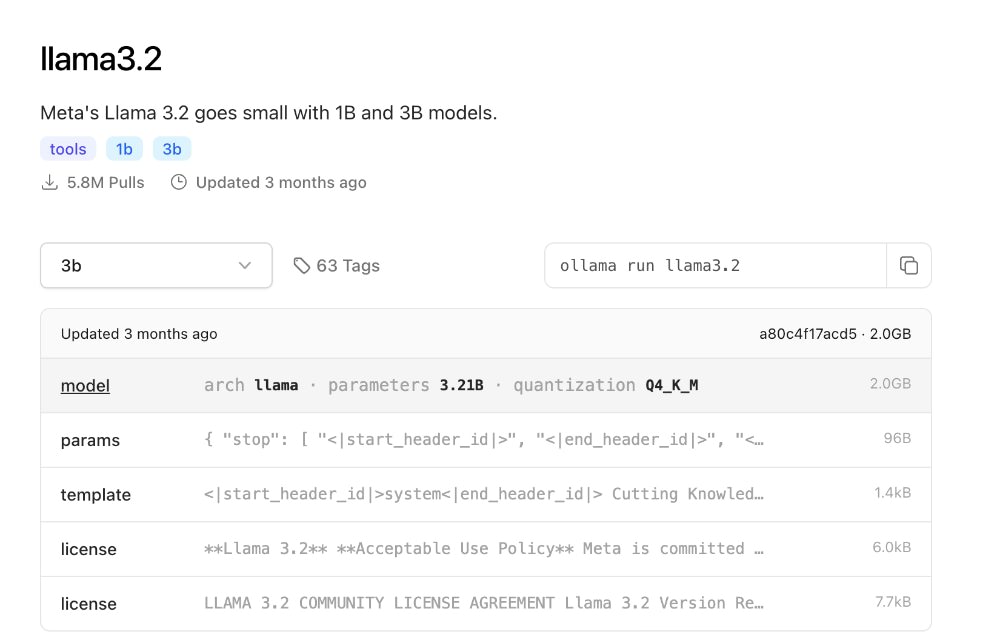
llama3.2 is a model from Meta designed for tasks like content creation, summarization, and retrieval-augmented generation (RAG). It supports multiple languages, including English, Spanish, and French, and is compact, making it perfect for lightweight applications. If you need more power, you can opt for a larger model like llama3.3 with 70 billion parameters. However, larger models require significantly more computing resources, so ensure your system can handle it before making the switch.
To use llama3.2 with Ollama, we can type:
ollama run llama3.2
If this is the first time you’re running this model, Ollama will download the model files and cache them on your computer. This process might take a few minutes depending on your internet speed.
After the download is complete, we can start interacting with it right from the terminal. It will provide you with a prompt where you can type your input, and the model will generate a response based on the input you provided.
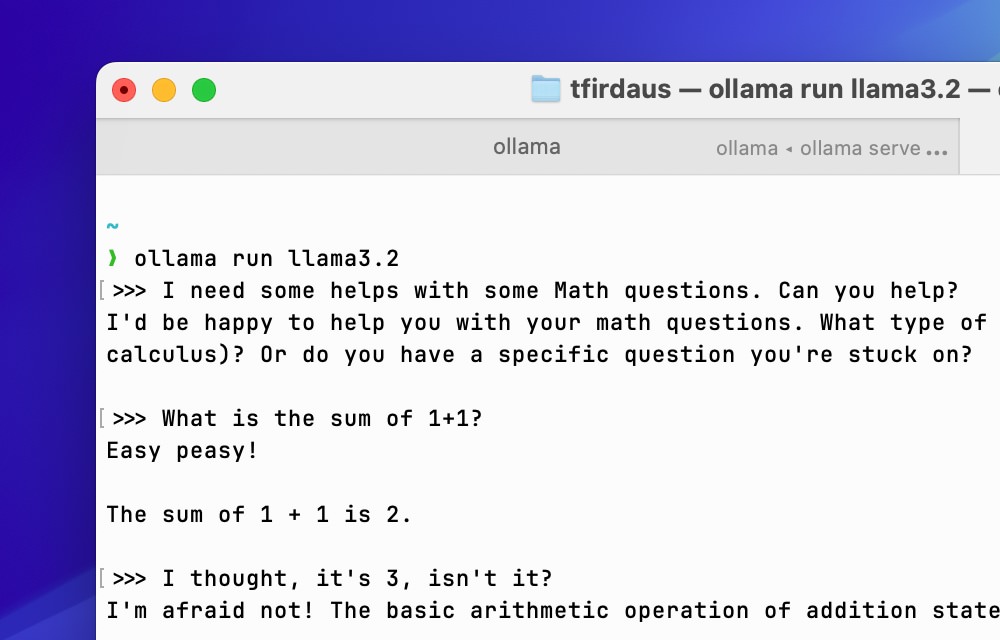
To exit the interaction with the current model in the Terminal, you can type /bye or press Ctrl/Cmd + D on your keyboard.
Ollama API
Ollama provides an API that allows you to interact with its models programmatically, which you can use to integrate it into your applications, websites, or other projects.
By default, the API is accessible at http://127.0.0.1:11434, and below are some of the key endpoints you can utilize for these purposes:
| Endpoint | Explanation |
|---|---|
POST /api/generate |
Generate a response for a given prompt with a provided model. |
POST /api/embed |
Generate an embedding for a given text with a provided model. |
GET /api/tags |
List available models on the local machine. |
GET /api/ps |
List models that are currently running. |
Ollama also provides SDKs for Python and JavaScript to make it easier to interact with the APIs.
OpenAI Compatibility
In addition to its own API, Ollama includes a compatibility layer for OpenAI’s API. This lets you reuse the code and SDKs designed for OpenAI’s API with Ollama, making it easier to transition between the two.
However, as of now, the compatibility layer is in beta, and some features may not work perfectly yet. For the best experience, it’s recommended to use Ollama’s API directly.
Conclusion
Ollama is a powerful and flexible tool for running AI locally, offering privacy, reliability, and full control over the models you run.
With its API and tools, Ollama opens endless possibilities for integrating AI into your projects. From generating quick responses to solving complex problems, it delivers a seamless and private experience.
Stay tuned for more tutorials where we’ll explore advanced features and use cases!