How to Run Chat Assistant that Works Offline
AI chat assistants have become essential tools for productivity and creativity. They can help with many things, from answering questions to doing some tasks automatically. But most of these tools need to connect to services, like OpenAI and Claude, which means you always need internet access. While it is convenient, it also raises concerns about privacy, data security, and reliance on external servers.
If you want to use AI chat assistants without these concerns, you can host and run your own AI models on your local machine or server. This allows you to have full control over your data, as well as the ability to customize the models to suit your needs.
In this article, we’ll show you how to host and use AI chat assistants using Open WebUI that work on your local machine or server, and could also work offline.
What is Open WebUI
Open WebUI is an open-source web interface designed for interacting with various Large Language Models (LLMs).
It comes with a number of features such as Retrieval Augmented Generation (RAG) support, image generation, Markdown and Latex support, web search support with SearXNG, Role-based Access Control, and a lot more which makes it comparable to popular services like ChatGPT and Claude.
System Prerequisites
To get the Open WebUI up and running, you’ll need the following:
- Docker: In this article we are going to use Docker to run Open WebUI. This way the application is contained and does not interfere directly with your computer system.
- Ollama: You will also need Ollama to run the models. Ollama is a tool that allows you to orchestrate multiple models. It is used to run the models in the Open WebUI. Follow the instructions on our article Getting Started with Ollama to install and set up Ollama in your computer.
After you have installed Docker and Ollama, make sure that you have Ollama running with the API accessible at 127.0.0.1:11434 or localhost:11434. You can check this by running the following command to get the version of Ollama:
curl http://localhost:11434/api/version
If it returns a version number, Ollama is running correctly and we are ready to proceed with the installation of Open WebUI.
System Requirements
Before installing Open WebUI and Ollama, ensure your system meets these minimum requirements:
Hardware Requirements:
| Component | Requirements |
|---|---|
| CPU | Modern multi-core processor (4+ cores recommended) |
| RAM | Minimum 8GB, 16GB or more recommended for larger models |
| Storage | At least 10GB free space for base installation, plus additional space for models:
|
| GPU | Optional but recommended for better performance:
|
Software Requirements:
| Component | Requirements |
|---|---|
| Operating System |
|
| Docker | Latest stable version |
| Browser | Modern web browser (Chrome, Firefox, Safari, or Edge) |
Note: These requirements are for running basic models. More demanding models or concurrent usage may require more powerful hardware.
Installation Process
To install and run Open WebUI, you can run the following command:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
If this is the first run, this command will download the open-webui Docker image. It may take a while but subsequent runs will be faster. Once the image is downloaded, it will start the container and you can access the Open WebUI at localhost:3000 in your browser.
Note, that if you see an error when loading it in the browser, wait a bit for a few minutes. It may still be initializing and downloading some resources in the background to complete the setup.
When you see the following screen, you have successfully installed Open WebUI and ready to get started.

Creating an Account
When you first access the Open WebUI, you will be prompted to create an admin account. You will need to input your name, email, and password.
After you have created an account, you will be immediately logged in and see the following interface.
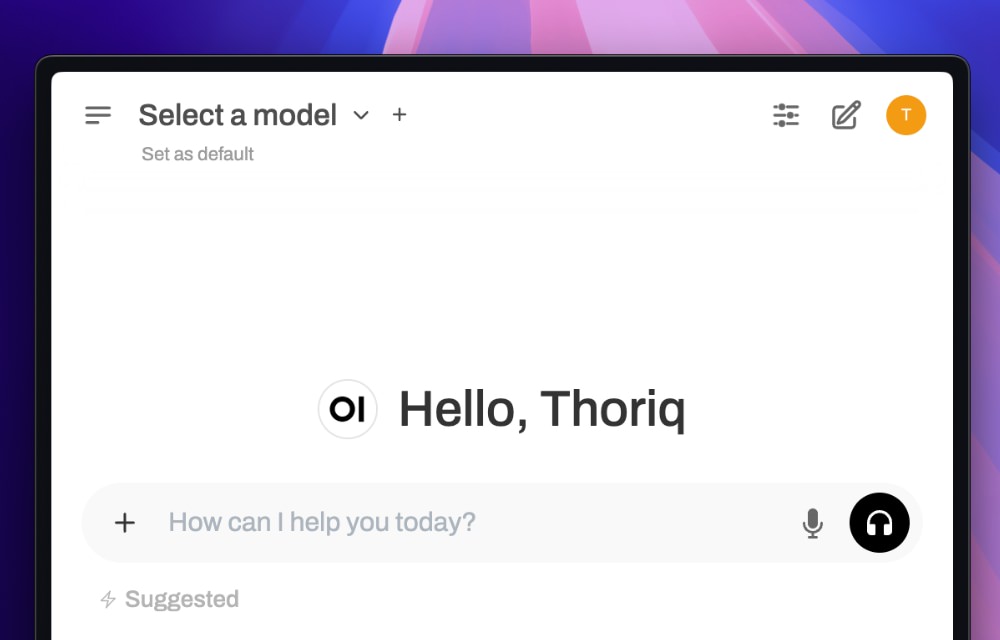
Selecting a Model
At this point, we still can’t interact with the chat assistant because we haven’t selected a model yet.
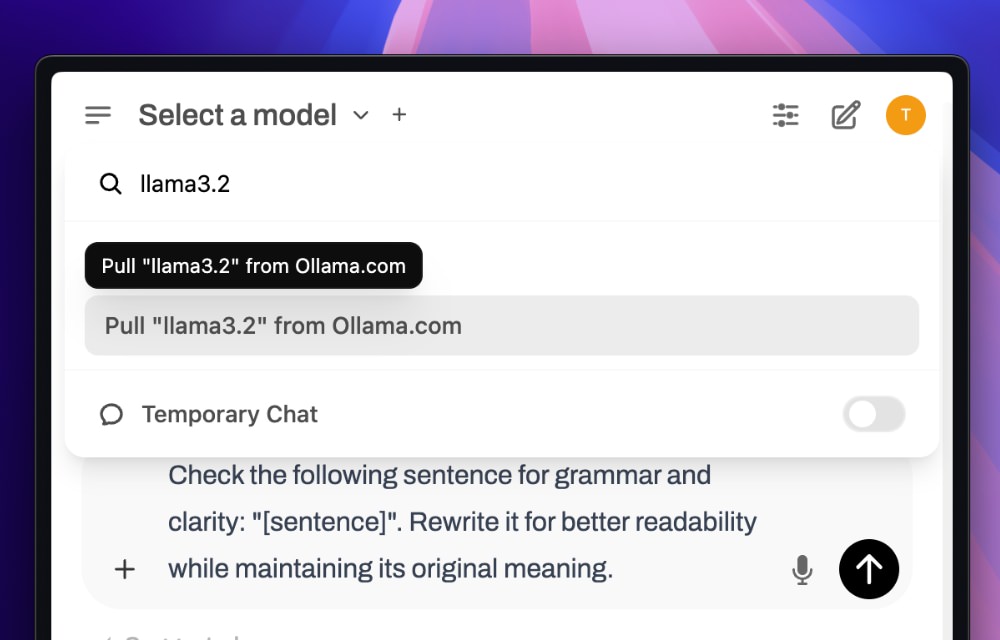
To download the model, you can click on the top “Select a model” option. Type in the model name e.g. llama3.2 and select the “Pull ‘llama3.2’ from Ollama.com”, as you can see below.
Alternatively, since the model is downloaded from the Ollama library, we can also download it directly with the Ollama CLI. In our case, to download the “llama3.2” model, we can run:
ollama pull llama3.2
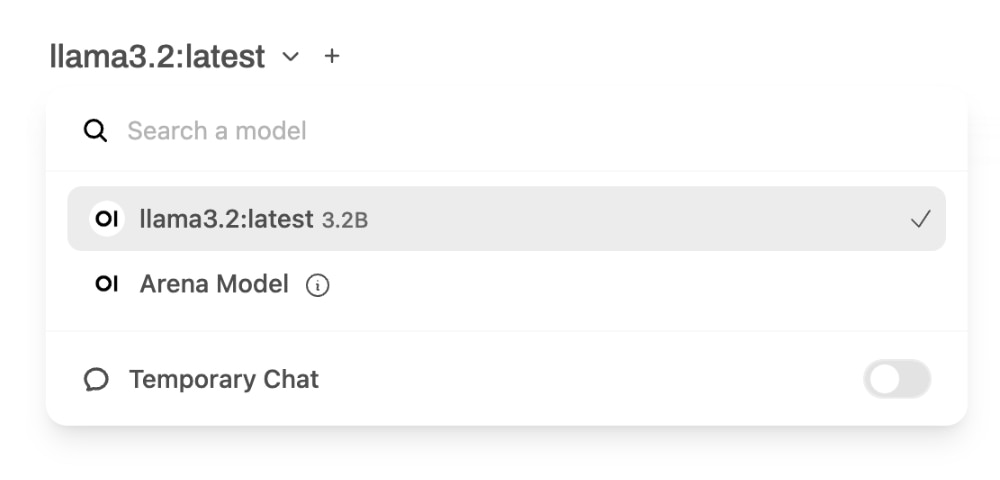
Again, this process will take some time to download the model. Once it is downloaded, you can select the model from the “Select a model” option.
Model Comparison Guide
Open WebUI supports various models through Ollama. Here’s a comparison of commonly used models to help you choose the right one for your needs:
| Model | Size | Key Features | Best For | Limitations |
|---|---|---|---|---|
| llama3.2 | ~4GB |
|
|
|
| llama3.2-vision | ~8GB |
|
|
|
When choosing a model, consider these factors:
- Hardware Capabilities: Ensure your system can handle the model’s requirements
- Use Case: Match the model’s capabilities to your specific needs
- Response Time: Larger models generally have slower response times
- Storage Space: Consider the available disk space for model storage
Interacting with the Chat Assistant
Once you have selected the model, you can start interacting with the chat assistant. You can type in your questions or prompts in the chat box and the chat assistant will respond accordingly.
The response would work best if you ask questions or prompts that are related to the model you have selected. For example, if you have selected the “llama3.2” model, you can ask questions related to general knowledge, trivia, or any other topic that the model is trained on.
For example, you can ask questions like:
- What is the capital of Indonesia?
- Who is the author of the book “Lord of the Ring”?
- What is the boiling point of water?
Keep in mind though the “llama3.2” may not be answering accurately for real-time events since the model is only trained with the data up to 2023.
Troubleshooting Guide
When using Open WebUI, you might encounter some common issues. Here’s how to resolve them:
Docker Container Won’t Start
- Symptom: Docker container fails to start or crashes immediately
- Check if port 3000 is already in use:
lsof -i :3000
If in use, either stop the conflicting service or change the port in the docker run command
- Verify Docker daemon is running:
systemctl status docker
- Check Docker logs:
docker logs open-webui
Connection to Ollama Failed
- Symptom: “Cannot connect to Ollama” error message
- Verify Ollama is running:
curl http://localhost:11434/api/version
- Check if Ollama is accessible from Docker:
docker exec open-webui curl http://host.docker.internal:11434/api/version
- Restart both services:
systemctl restart ollama docker restart open-webui
Model Download Issues
- Symptom: Model download fails or times out
- Check available disk space:
df -h
- Try downloading through Ollama CLI:
ollama pull modelname
- Clear Ollama cache and retry:
rm -rf ~/.ollama/models/*
Advanced Features
Using RAG (Retrieval Augmented Generation)
RAG allows you to enhance the model’s responses with your own knowledge base. Here’s how to set it up:
1. Prepare Your Documents Your knowledge base can include PDF, TXT, DOCX, and MD files. Simply place these documents in the designated knowledge base directory, making sure they’re properly formatted and readable.
2. Configure RAG Settings
{
"rag_enabled": true,
"chunk_size": 500,
"chunk_overlap": 50,
"document_lang": "en"
}
Setting Up Web Search with SearXNG
Integrate web search capabilities into your chat assistant:
docker run -d \ --name searxng \ -p 8080:8080 \ -v searxng-data:/etc/searxng \ searxng/searxng
Then configure Open WebUI to use SearXNG:
- Go to Settings > Advanced
- Enable Web Search
- Enter SearXNG URL:
http://localhost:8080 - Configure search parameters (optional)
Role-based Access Control
Configure different user roles and permissions:
| Role | Permissions | Use Case |
|---|---|---|
| Admin | Full system access | System management |
| Power User | Model management, RAG configuration | Advanced users |
| Basic User | Chat interaction only | Regular users |
Leveraging Multimodal Capabilities
Open WebUI also supports multimodal capabilities, which means you can generate images along with text or use an image as part of your prompt inputs.
To do so, however, you’d need a model with multimodal capabilities. In this example, we can use the “llama3.2-vision”. You can download the model from the Open WebUI interface as we did before or use the Ollama CLI to download it directly:
ollama pull llama3.2-vision
After it’s downloaded, select the model and upload an image to the chat assistant. You can do this by clicking on the + button and submit it along with your prompt.
In this example, I’d use an image, The Red Bicycle from Openverse and ask What’s the primary focus of this picture?
.
Indeed, it is able to answer the question, and it even knows the color of the bicycle, as we can see below.

Wrapping Up
Open WebUI is a powerful tool that allows you to host and use AI chat assistants on your local machine or server. It provides a user-friendly interface for interacting with various Large Language Models (LLMs).
It’s a perfect tool for those who are concerned about privacy, data security, and reliance on external servers. With Open WebUI, you can have full control over your data and privacy, as well as the ability to customize the models to suit your needs.
It is also a great tool for developers who want to experiment with AI chat assistants and build their own custom models. With Open WebUI, you can easily host and run your models, and interact with them using a simple and intuitive interface.