3 Powerful Things You Can Do with Vision-Enabled Models in Ollama
Artificial intelligence keeps getting smarter, and vision-enabled language models are becoming essential tools for developers. These clever models can analyze images and describe them in plain English. By combining language understanding with computer vision, they can spot objects, details, or potential issues in visual content.
In this article, we’ll look into three practical ways you can use vision-enabled models in Ollama:
Selecting Programming Language
Before we dive into these specific applications, let’s discuss our choice of the programming language.
We’ll be using PHP
Why?
I understand PHP might not be people’s first choice when working with AI. Many would opt to use Python.
However, I think PHP actually works great with LLMs. PHP can often run faster than Python in many cases, making it ideal for building AI applications. With built-in features for handling HTTP requests and JSON, it’s also easy to work with Ollama’s API.
Selecting a Model
Next, we are going to select the model to use.
There are several vision-enabled models available in Ollama. It provides models with vision capabilities like LLaVA or llama3.2-vision.
For this article, we’ll be using the llama3.2-vision model. It’s two times larger than the llava model, but it’s also more powerful and accurate.
Pre-requisites
That said, to build the applications in this article, you will need the following installed and set up on your computer:
- Ollama: We’ll use Ollama to download the model and run it locally. You can follow our article, Getting Started with Ollama, to learn how to install and set up Ollama on your computer.
- PHP: The programming language we’ll use to build our applications. Check out our article, 5 Ways to Manage Multiple Versions of PHP, to manage PHP installations on your computer.
After you have Ollama running, we can download llama3.2-vision by running the following command.
ollama pull llama3.2-vision
Then, we can start building and running our applications.
1. Image-to-Text Generation
One of the most useful features of vision-enabled models is their ability to describe images. These models can create captions, descriptions, and alt text that help make images accessible and understandable to everyone. Let’s take a look at how we can implement this feature.
I’ve created a simple class called AltText that handles the conversion:
class AltText implements Prompt {
use WithOllama;
public function fromImage(string $image): string {
// Parse the image, send prompt to Ollama, and return the response.
}
}
The fromImage method takes an image path as input. It then encodes the image and sends it to Ollama for processing.
Rather than diving into the PHP implementation details, which you can find in our ollama-vision-enabled-llms repository, let’s focus on the key part: the prompt we send to Ollama. Here’s what we use to generate the alt text:
Generate concise, descriptive alt text for this image that: 1. Describes key visual elements and their relationships 2. Provides context and purpose 3. Avoids redundant phrases like "image of" or "picture of" 4. Includes any relevant text visible in the image 5. Follows WCAG guidelines (130 characters max) Format as a single, clear sentence.
Let’s try this with an example image:

To generate alt text for this image, we can call our class like below:
echo (new AltText())->fromImage('./img/image-1.jpg');
When we run this code, the model generates a pretty accurate description of the image, as shown below:
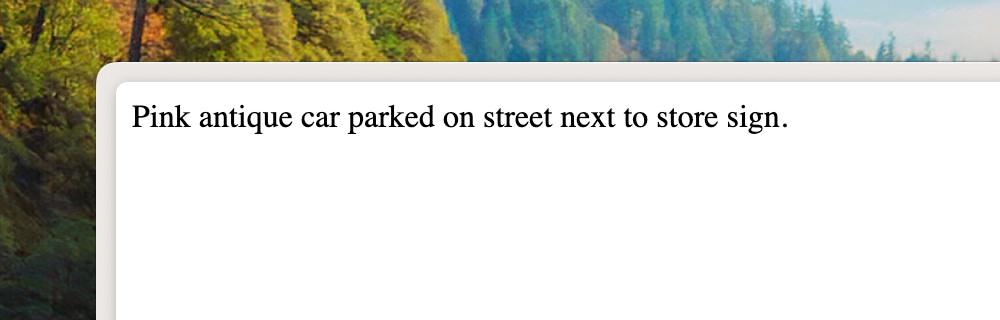
2. Visual Data Extraction
Another useful capability of vision-enabled models is their ability to recognize and extract text from images, also known as Optical Character Recognition (OCR).
These models can understand content structures such as tables, which could be particularly useful when you’re working with screenshots of data tables, financial reports, or any tabular information trapped in image format.
Let’s create a simple tool that extracts tables from images and formats them as Markdown. This tool uses a class implementing the Prompt interface, as shown below, following a similar structure to our earlier application.
class TableExtractor implements Prompt {
use WithOllama;
public function fromImage(string $image): string {
// Parse the image, send prompt to Ollama, and return the response.
}
}
The difference would be in our prompt. In this example, our prompt focuses on extracting the table from the image:
Extract the table from this image and format it as a Markdown table
with the following requirements:
1. Identify and include all column headers
2. Preserve all data in each cell
3. Maintain the alignment and relationships between columns
4. Format output using Markdown table syntax:
- Use | to separate columns
- Use - for the header separator row
- Align numbers to the right
- Align text to the left
Response should only contain the Markdown formatted table, without
any additional or explanatory text or list before or after the table.
Let’s try this with the image below.
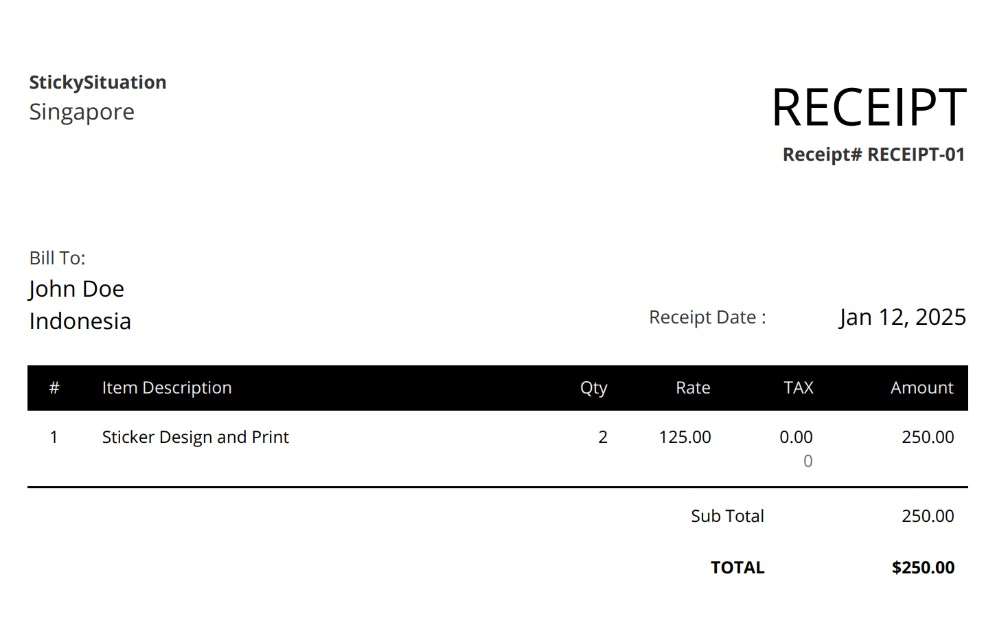
Using our class, we can extract the table from the image and format it as Markdown using the Parsedown, like below:
echo (new Parsedown())->text(
(new TableExtractor())->fromImage('./img/image-2.jpg')
);
The result, as expected, is a Markdown formatted table extracted from the image pretty accurately. Although, in this case, it also responds with the table headers as a list, somehow, as we can see below. I think we’d need to recalibrate the prompt, but for now I’m pretty happy with the result.

You can see the full source of the code implementation in the repository.
3. Visual and Accessibility Testing
Not everyone experiences websites the same way. Some people find it hard to read certain colors or need bigger text to read comfortably. Others might struggle with small buttons or low-contrast text.
This is also where vision-enabled models can help. We’ll use them to automatically check our websites for these accessibility issues. So we can make sure our websites are more accessible and create a better experience for as many users as possible.
Let’s create a simple tool that checks a website for accessibility issues. It also uses a class implementing the Prompt interface, as shown below:
class VisualTesting implements Prompt {
use WithOllama;
public function fromUrl(string $url): string {
// Parse the URL, send prompt to Ollama, and return the response.
}
}
We’ll be adding the prompt to check a few relevant accessibility issues that can be observed from just an image, as follows:
Analyze this UI screenshot for color contrast issues, which includes: - Text vs background contrast ratios for all content. - Identify any text below WCAG 2.1 AA standards. - Flag low-contrast text.
We’ll try this prompt with the image below.
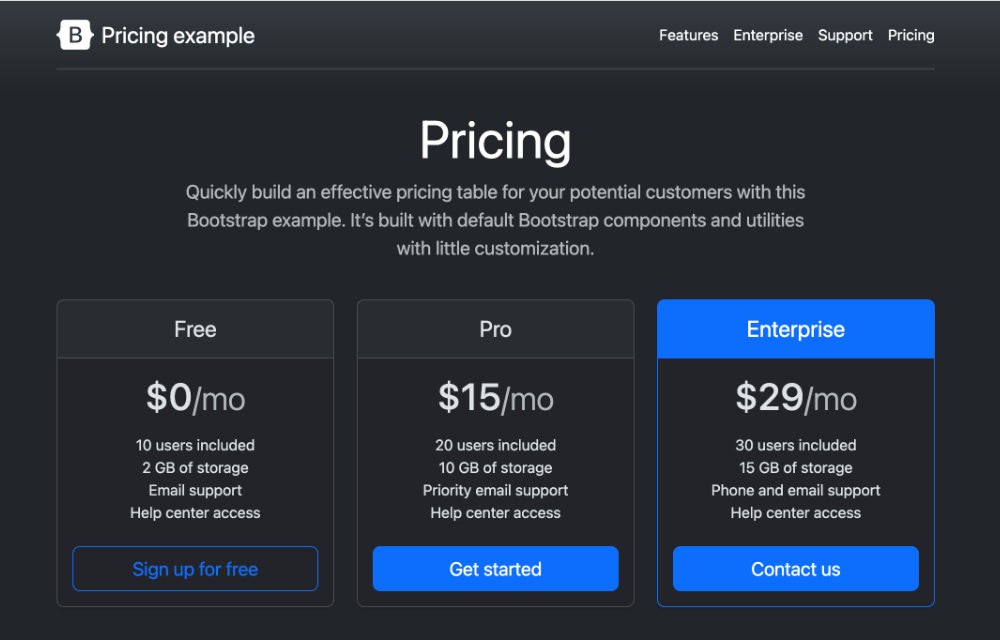
Using our class, we can check the image for accessibility issues using the Parsedown, like below:
echo (new VisualTesting())->fromUrl('./img/image-3.jpg');
The model can accurately recognize what the image is about and provide an assessment of the accessibility issues. The response is shown below:

However, I found the results could sometimes be hit or miss, and it can run really slow depending on the details in the image being processed. So we might need to fine-tune the model configuration, use a model with higher parameters, and run it on better hardware.
Wrapping
Vision-enabled models open up smart and efficient ways to work with images. They simplify tasks like generating image descriptions, extracting data, and enhancing accessibility – all with just a few lines of code. While the examples we’ve explored are just the beginning, there’s room for improvement, such as fine-tuning models or crafting better prompts for more accurate results.
As AI continues to evolve, adding vision capabilities to your workflow can help you create more powerful and user-friendly applications. It’s something that I think you should definitely consider exploring.